When does agency earn its cost? Benchmarking LLM extraction strategies on legal documents

Look at almost any enterprise that runs on paperwork and you’ll find the same workflow happening on repeat: a person (or a team of people) reading a bunch of documents, finding the same handful of fields, and typing them into a system of record. It’s the kind of work that scales linearly with headcount and never quite finishes.
The research literature calls it Key Information Extraction, and when Applica AI released the Kleister benchmark in 2021, they were blunt: “Kleister datasets for the Key Information Extraction task are challenging and hardly any solutions in the current NLP world can solve them.”
That was before the frontier shifted. The interesting question isn’t whether LLMs can do this now, it’s whether the sophisticated way of doing it (an agent that reads the document tool call by tool call, decides what it needs, and assembles an answer) actually beats the simple way (one structured call over the whole document).
This post is about what happens when you actually run that comparison: three model providers, two capability tiers, two extraction strategies, benchmarked on a real corpus of NDAs from SEC Edgar.
Getting there required a few pieces of machinery: a reproducible preprocessing pipeline for the dataset, a typed Python library that abstracts both extraction strategies behind a shared contract, and an evaluation harness that scores them against the same ground truth. What follows is how those pieces came together and what the numbers said once they did.
Dataset preprocessing
Before any of the interesting questions about extraction strategies can be asked, there has to be a dataset. A benchmark where the inputs are real documents, the labels are trustworthy, and the whole thing can be rebuilt from scratch with a single command. Without that foundation, every downstream result is unfalsifiable.
So this is where we’ll start: a small, focused Python package whose only job is to take the raw Kleister NDA distribution and hand back something a modern extraction pipeline can actually stand on—PDFs on disk, structured labels in Parquet, all validated against a Pydantic schema that the extractors will later share.
Reproducibility and shared data contracts
The preprocessing lives in its own repository: kleister-nda-preparation. It exposes a single CLI command that reads the original TSV partitions, parses the raw label strings, relocates the PDFs, and writes partitioned Parquet files.
Installing it as a dependency means downstream projects—the core library, the evals harness, and, in part two, the deployment layer—all consume the same canonical form.
Kleister NDA
Kleister NDA is a 540-document corpus of Non-Disclosure Agreements collected from SEC Edgar, released by Applica AI as part of a broader benchmark for Key Information Extraction on long, layout-rich business documents.
Each NDA is annotated with up to four fields:
- the
effective_dateon which the contract becomes binding, - the
jurisdictiongoverning it, - the
partyor parties entering the agreement, and - the
termspecifying its duration.
Here’s an example of how the document’s layout looks in practice:

A few properties make it a genuinely useful benchmark rather than a toy dataset:
- First, the documents are real: they were submitted as attachments to SEC filings by actual companies, so the layouts, the legalese, and the edge cases are all authentic.
- Second, they’re long enough to matter: most run between one and twenty pages, which is past the point where naive “dump the whole thing into a prompt” strategies start to feel uncomfortable.
- Third, the normalization rules are strict: dates must be ISO 8601, terms must be reduced to
{number}_{units}, and jurisdictions must be the bare name with no honorifics. That last detail is what makes the evaluation non-trivial. A model that returnsState of New Yorkwhen the ground truth isNew_Yorkis wrong, even though someone might call it a draw.
Baseline expectations
The original paper (Stanisławek et al., 2021) sets a useful anchor for expectations. Their best baseline, a layout-aware model called LAMBERT built on top of BERT, reached an overall F1 of 81.77% on the NDA test set. That’s the number to keep in mind as the rest of this post unfolds—it’s what the pre-LLM state of the art looked like, and it’s what a well-configured LLM extractor should be comfortably surpassing if the strategy is sound.
Exploratory data analysis
Before a line of extraction code was written, there was a notebook. The short version of what the EDA surfaced is that the document length distribution is right-skewed with a heavy tail—most NDAs are three to seven pages, but a handful stretch past twenty.
Document length distributions
Distributions of token, character, and page counts across train, dev, and test partitions
EDA for NDAs
The full EDA notebook, with every plot and the code that produced it, lives at notebooks/initial-eda.ipynb. It’s worth a scroll if you want to see what the data looks like before any machinery touches it.
The EDA surfaced three patterns, and each pulled the design in a specific direction.
- The length distribution is right-skewed. Most NDAs sit comfortably in the 3,000-5,000 token range across three to seven pages, but all three partitions exhibit the same long-tail behavior, with outliers stretching to roughly 14,000 tokens and 23 pages.
- Null rates vary wildly across fields.
partyis never null.jurisdictionis rarely null.effective_dateis absent in roughly 25-30% of documents, andtermis absent in approximately 60-70%. Fields with high null rates are the ones where hallucination risk is highest. - The bundled OCR text is dirtier than it needs to be. On the same PDFs,
text_best(the OCR-derived text shipped with the dataset) and text extracted directly via PyMuPDF show near-perfect length correlation but Jaccard similarity peaking around 0.70-0.75—same size, although ~25-30% of tokens disagree. That’s the signature of OCR noise on born-digital documents: character-level garbling preserves string length while corrupting tokens the extractor would otherwise get for free. This shaped a library-level decision: extract from the text layer by default, and expose anOCRProviderprotocol so scanned documents remain a first-class case. For Kleister, PyMuPDF is the right call.
Schema as contract and steering mechanism
The single most important design decision in this project is also the least visible: the Pydantic schema isn’t just a type. It’s the contract, the validator, and the prompt—all at once.
Here’s a small piece of what that means in practice:
from pydantic import BaseModel, Field
class NDA(BaseModel):
"""
Extract key information from a Non-Disclosure Agreement (NDA).
General formatting rules:
* In attribute values, replace spaces ` ` and colons `:` with underscores `_`.
* If an attribute is not present or cannot be determined, return `null`.
"""
jurisdiction: str | None = Field(
None,
description=(
"The state or country under whose laws the contract is governed. "
"Return only the name (e.g., `New_York`, `Delaware`, `Florida`). "
"Do NOT include prefixes such as `State_of_` or `Commonwealth_of_`."
),
)Schema as the single source of truth for extraction behavior
The complete schema, including field validators, lives at src/nda/schema.py. It is worth a read to see how the contract, the validation, and the prompt engineering are all encoded in one place.
Three things are happening here simultaneously, so let’s pull them apart one by one.
- The first is the contract. Any code that consumes an extraction result (the evaluation harness, or a downstream application) can rely on the fact that
jurisdictionis either a string orNone, thatpartyis always a list, that dates are strings in ISO format. This is absolutely crucial for production use. - The second is the validation layer. The schema doesn’t just describe the shape of the output; it enforces it. When a model returns a jurisdiction with an unwanted
State_of_prefix, a field validator strips it. When a party name comes back wrapped in unicode smart quotes, those get normalized to ASCII. The validation runs symmetrically at preprocessing time (cleaning the ground truth labels) and at inference time (cleaning the predictions), which means the evaluation is comparing apples with apples rather than measuring a normalization mismatch masquerading as a model error. - The third is the steering mechanism. LangChain’s
with_structured_output(NDA)serializes the Pydantic class into the function-calling schema the model sees at inference time. That means the class-level docstring, the field types, and everydescriptionstring on everyField, all become part of the prompt. The model doesn’t see a generic “extract these fields” instruction; it sees the exact formatting rules, the specific prefixes to avoid, the concrete examples of valid output.
Schema-driven iteration
This reframes how you iterate on extraction quality. When an LLM is systematically over-specifying jurisdictions, you don’t reach for a separate prompt file and start tweaking system instructions, you edit the description on the jurisdiction field and the change propagates everywhere.
We want the schema to be the single surface where extraction behavior is calibrated, which keeps the system prompt stable and the behavioral changes auditable via git history.
Package architecture
With a trustworthy benchmark in place, the next question is what actually runs against it. The extraction logic could have lived in the evals repository as a handful of scripts, but that collapses the distinction between the thing being measured and the thing doing the measuring.
Keeping them separate means the library has to stand on its own: a clean API, a typed contract, and a set of abstractions that make sense outside the context of Kleister.
The result is agentic-kie, a Python package whose job is to take a PDF and a Pydantic schema and return a validated instance of that schema. Everything else (text-layer detection, OCR routing, image rendering, agent orchestration) is an implementation detail the caller doesn’t have to think about.
The public API
The shape of the public API is the most important design choice in the package. Everything downstream follows from it. Here’s what a typical call looks like:
from pathlib import Path
from nda import NDA
from langchain_anthropic import ChatAnthropic
from agentic_kie import PDFLoader, AgenticExtractor
file_path = Path("nda.pdf")
document = PDFLoader().load(file_path)
model = ChatAnthropic(model="claude-haiku-4-5")
agent = AgenticExtractor(model=model, schema=NDA)
result = agent.extract(document)Four lines do the work: load the PDF, instantiate a model, wrap it in an extractor bound to a schema, and extract. The extractor doesn’t know what model it’s using. The model doesn’t know what document it’s reading. The schema doesn’t know either of them exist. That separation is deliberate—each piece is independently swappable, which is what makes the benchmarking in the next section possible in the first place.
Packaged and distributed on PyPI
The library is published as agentic-kie and installable via uv add agentic-kie, with optional extras for each model provider ([anthropic], [google], [openai], [bedrock], or [all]). Any LangChain chat model would do, the extras are provided as a convenience.
The four core abstractions—PDFLoader, PDFDocument, OCRProvider, and the Extractor protocol—are covered in detail in the README, so I’ll spare the recap.
What’s worth saying here is that the package is organized around a single axis of responsibility: ingestion is separate from representation, representation is separate from extraction, and extraction strategies are swappable behind a shared protocol. That organization is what the rest of this section is really about.
Extraction strategies
Two strategies are available, and they satisfy the same Extractor protocol—a single extract(document) -> T method that takes a PDFDocument and returns a validated instance of the schema. Same input, same output, entirely different machinery in between.
- Single-pass is the obvious baseline: one structured LLM call over the full document, with the schema bound via function calling. The chain is built once at construction time and reused across documents. Fast, cheap, stateless, and—as the evals in the next section will show—surprisingly hard to beat.
- Agentic is the more interesting bet. A ReAct loop equipped with document tools (
get_page_count,read_text,load_images) scoped to the specific document being extracted. The agent reads what it needs, in the order it needs it, and stops when it has enough information to fill the schema. More expensive per call, more resilient to document length, and more to prove.
Here’s what the internal graph of the agentic extractor looks like in LangGraph Studio:
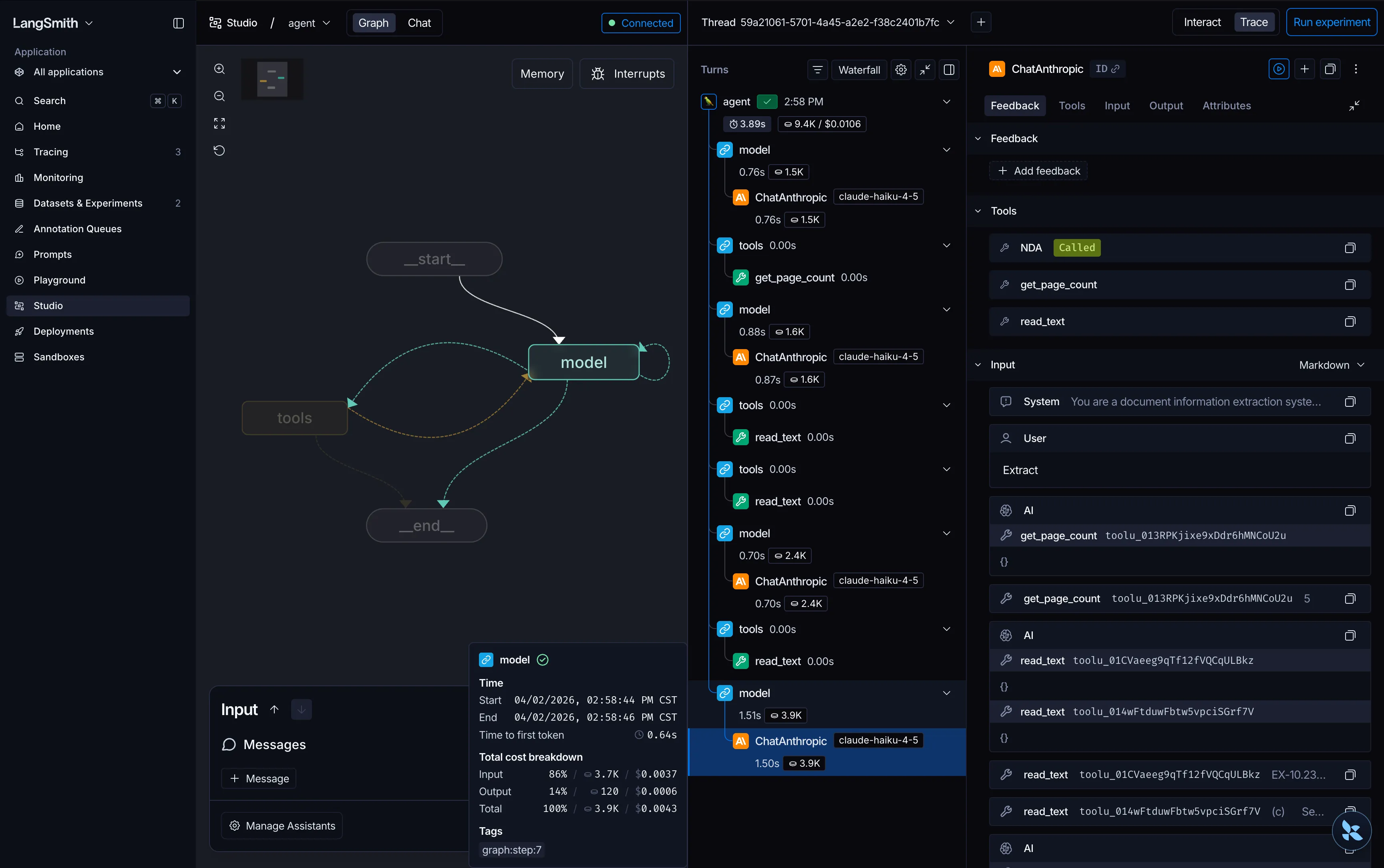
One protocol, two strategies
The full implementation of both extractors, including the document tool factory and the ReAct loop, lives at src/agentic_kie/. The examples/ directory has runnable scripts that demonstrate both strategies across providers using the Kleister NDA dataset.
Design arguments
Two design decisions shaped the package in ways that aren’t visible from the API but would have been painful to get wrong.
The first was decoupling loading from representation. PDFLoader absorbs all the messiness of the real world: detecting whether a text layer exists, routing to OCR when it doesn’t, and validating the result. PDFDocument is immutable, renders images lazily on first access, and serves both text-only and multimodal strategies without knowing which one is about to consume it. More broadly, agentic behavior exists on a spectrum, and this extraction task has a closed-loop boundary, so the agent doesn’t need much freedom. It needs a small, curated interface over a trustworthy representation, not a full-blown REPL environment.
The second was choosing protocol over inheritance for Extractor[T]. Single-pass and agentic satisfy the same extract(document) -> T contract without being forced into a shared inheritance tree. The two strategies have genuinely nothing in common internally, and pretending otherwise by sharing a base class would have been a lie dressed up as code reuse. A structural protocol gives type-safe dispatch at the boundaries where it matters (the evals harness can accept any Extractor[NDA], for example) without coupling the implementations.
Evaluations
With the dataset prepared and the library in place, the question shifts from “can we extract?” to “how well, at what cost, and under what conditions?” The benchmark covers three model providers (Anthropic, Google, and OpenAI) across two capability tiers each (selecting each provider’s current offering per tier as of early 2026) crossed with both extraction strategies.
Twelve configurations in total, scored against the same 83 documents from the dev partition.
Model tiers by provider
Models used in lite and standard evaluation tiers across the three model providers
| Provider | Lite | Standard |
|---|---|---|
| Anthropic | Claude Haiku 4.5 | Claude Sonnet 4.6 |
| Gemini 3.1 Flash Lite (Preview) | Gemini 3 Flash (Preview) | |
| OpenAI | GPT 5.4 Mini | GPT 5.4 |
Scope of this benchmark
All results below are computed on the Kleister NDA dev-0 partition (83 documents). This is large enough to rank configurations and identify consistent patterns, though the findings would naturally strengthen with a larger sample. The test-A partition remains available for anyone who wants to extend the analysis.
Running experiments
Each configuration runs as a LangSmith experiment. The NDA dataset (PDFs plus labels_schema as reference outputs) is uploaded once as a multimodal dataset with PDF attachments, and every experiment evaluates against the same examples with the same evaluators.
Here’s an example of what an experiment run looks like in the LangSmith UI:
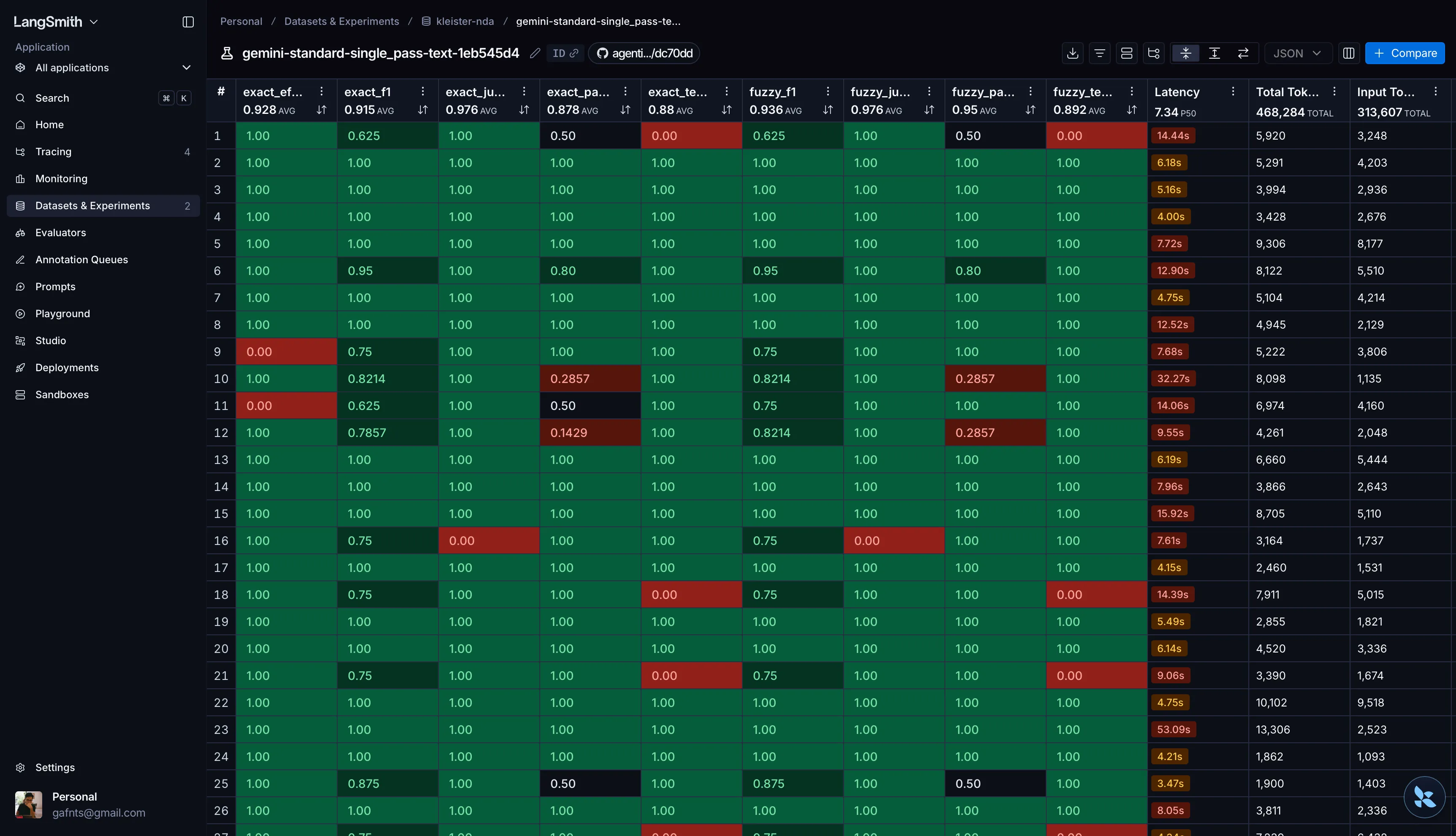
Reproducing the benchmark
The full benchmarking harness (dataset upload, experiment runner, evaluators, and aggregation scripts) lives at agentic-kie-evals. The raw results for every configuration are published under data/results as per-document CSVs alongside aggregated summaries, so the numbers in this post are auditable end-to-end.
Results
Before interpreting any numbers, it helps to anchor against what the field already knows. The original Kleister paper reports a 81.77% F1 for their best layout-aware baseline (LAMBERT) and a 97.86% F1 for human annotators on the NDA test set.
Here’s the top five configurations from the benchmark, sorted by overall F1 and annotated with the average cost and latency per document:
Top five extraction configurations
Best-performing configurations ranked by F1, with latency and cost context
| Provider | Tier | Strategy | F1 Score | Latency | Cost |
|---|---|---|---|---|---|
| Gemini | Standard | Agentic | 91.8% | 14.6s | $0.011 |
| Gemini | Standard | Single Pass | 91.5% | 9.8s | $0.007 |
| GPT | Standard | Single Pass | 89.9% | 2.1s | $0.011 |
| Gemini | Lite | Single Pass | 89.6% | 1.4s | $0.001 |
| GPT | Standard | Agentic | 89.5% | 8.5s | $0.024 |
The top of the matrix is essentially a tie between the Gemini family configurations, with GPT close behind. Gemini Standard Agentic edges out at 91.8% F1, but Gemini Standard Single Pass reaches 91.5% at roughly 70% of the cost and 65% of the latency. Notably, every top-five configuration clears the LAMBERT baseline by a healthy margin, with the best results sitting about six points below the human ceiling.
Looking across all twelve configurations, a consistent pattern emerges. Across every provider and tier, the F1 gap between agentic and single-pass narrows as model capability increases. At the lite tier, single-pass wins across all three providers. At the standard tier, the strategies converge, with Claude and Gemini showing the agentic approach pulling slightly ahead.
Strategy comparison by provider and tier
Agentic vs. single pass across Claude, Gemini, and GPT
Latency and cost are where the asymmetry becomes stark. As is to be expected, agentic extraction is consistently slower and more expensive than single-pass, with Claude Standard Agentic hitting ~65 seconds per document at ~$0.038. For a strategy that delivers, at best, a modest F1 improvement at the top of the matrix, that’s a steep price. The lite-tier agentic runs are the worst of both worlds: slower, more expensive, and less accurate than their single-pass counterparts.
Per-field failure analysis
Aggregate F1 hides the failure modes that actually explain the benchmark. Breaking results down per field (effective_date, party, jurisdiction, and term) surfaces a pattern that holds across every provider and tier.
Where extraction breaks down
Exact F1 by field across all configurations
The paper flagged term as the hardest entity for the pre-LLM baselines (LAMBERT scored 55.03% F1 on it), and the LLM results confirm this is still the most pervasive failure mode. All three model families consistently confuse sub-clause durations (confidentiality survival periods, non-compete restricted periods) with the overall agreement term. The schema’s field description tries to steer the model toward the agreement duration specifically, but when a document contains multiple duration clauses, the lite-tier models reach for whichever one is most prominent in the text.
The field ranking is stable across configurations, but the depth of the failure varies dramatically under agentic orchestration. Claude Lite Agentic and GPT Lite Agentic both bottom out on the same two fields: jurisdiction (63.9% and 51.8%) and term (66.3% and 56.6%). The paper’s baselines aren’t a flattering comparison in this case: LAMBERT reached 96.50% on jurisdiction and Flair topped the term field at 60.33%. A modern frontier-lab model running an agentic loop can regress below what pre-LLM baselines managed on the same fields. The task isn’t what changes. The capacity to execute it under agentic orchestration is.
When does agency earn its cost?
This is the question that drives the two-strategy architecture in the first place. The aggregate numbers suggest agency rarely pays for itself, but aggregates can hide document-level dynamics.
Plotting the per-document F1 delta between agentic and single-pass—faceted by provider, tier, and document length—sharpens the picture.
Agentic's document-level impact depends heavily on tier
F1 delta (agentic - single pass) per document, by provider, tier, and document length
F1 delta (agentic - single pass)
The lite tier tells a consistent story across all three providers: agency regresses more documents than it improves, and the red clusters dominate at every length bucket. GPT Lite Agentic is the worst offender, regressing 22 short documents with an average delta of -0.44 F1 per document. Even for Gemini 3.1 Flash Lite, the best of the lite tier models, the improvements are small and scattered while the regressions are concentrated and severe.
The standard tier flips the dynamic. Unchanged outcomes dominate—the gray circles swell to 40+ observations per bucket—meaning the agent and the single-pass extractor land on the same answer most of the time. When they diverge, the improvements are larger and the regressions are rarer. Claude Standard Agentic shows a striking +0.60 improvement on short documents where it does make a difference, and GPT Standard Agentic shows a clean +0.83 improvement on a very-long document that single-pass couldn’t handle.
The pattern has two compounding mechanisms. Single-pass extraction is one decision; agentic extraction is dozens of them, and each decision requires meta-reasoning that lite models are less equipped for. The extraction task itself isn’t harder under agency; the orchestration around it is. And the orchestration has a second cost on top of the first: the agent has to accumulate extracted facts across tool calls and then synthesize them into the final schema. That’s a harder working-memory problem than producing structured output from a single context window, and lite models appear more prone to forgetting or contradicting their earlier observations.
A clean counterexample to the 'throw agents at everything' mindset
The default move in LLM engineering right now is to wrap a task in an agent loop and see what happens. This benchmark is a reminder that the default isn’t free: on the wrong task, or with the wrong model, it’s actively worse than doing the simple thing.
So, when does agency earn its cost? On this benchmark, it doesn’t. The simpler approach dominates most of the matrix and actively degrades performance on lite-tier models, while the standard-tier gains are too small to justify the 2-4x latency and cost. That’s a rare and useful data point against the reflex of wrapping every task in an agent loop, and the kind of answer that’s only visible once you’ve built both strategies and run the comparison.
What’s next?
Let me take a moment to note what this benchmark is and isn’t. The conclusion that single-pass dominates isn’t a universal—it’s a finding about Kleister NDA specifically, with a particular schema, document length distribution, and field structure. Different domains will naturally surface different dynamics.
The two-strategy architecture in agentic-kie exists because the right answer to “should this be an agent or a workflow?” is rarely obvious a priori; it’s something you learn by building both and measuring. That learning loop—pick a task, build both strategies behind a shared protocol, measure, then decide—is the deliverable. The negative result on agency is the proof that it works.
So with the matrix measured and the winner identified, the engineering question shifts from “which configuration?” to “how do we run it in production?”. Gemini 3 Flash (the standard-tier Gemini model) running single-pass extraction is what the benchmark points to: 91.5% F1 at ~$0.007 per document and under ten seconds of latency, comfortably past the LAMBERT baseline and within striking distance of human-level.
Part two takes that configuration and wires it into a production pipeline scaled for volume. See you there.