¿Cuándo vale la pena un agente? Una evaluación comparativa de estrategias de extracción con LLMs sobre documentos legales

Si observas casi cualquier empresa que funcione con papeleo, encontrarás el mismo flujo de trabajo repitiéndose en bucle: una persona (o un equipo) leyendo una pila de documentos, ubicando el mismo puñado de campos, y tecleándolos en un sistema de registro. Es el tipo de trabajo que escala linealmente con la cantidad de personas y que nunca termina del todo.
La literatura académica lo llama Key Information Extraction, y cuando Applica AI publicó el benchmark Kleister en 2021, fueron directos: “los datasets de Kleister para la tarea de Key Information Extraction son desafiantes y muy pocas soluciones en el mundo del NLP actual pueden resolverlos.”
Eso fue antes del cambio de paradigma. La pregunta interesante ya no es si un LLM puede resolver esto, sino si la forma sofisticada de hacerlo (un agente que lee el documento llamada por llamada, decide qué necesita, y ensambla una respuesta) realmente le gana a la forma simple (una sola llamada estructurada sobre el documento completo).
Este post trata sobre lo que pasa cuando esa comparación se ejecuta sistemáticamente: tres proveedores de modelos, dos tiers de capacidad, dos estrategias de extracción, medidos sobre un corpus real de NDAs obtenidos de SEC Edgar.
Llegar hasta aquí requirió de unas cuantas piezas de infraestructura: un pipeline de preprocesamiento reproducible para el dataset, una librería de Python tipada que abstrae ambas estrategias de extracción detrás de un contrato compartido, y un harness de evaluación que las puntúa contra el mismo ground truth. Lo que sigue es cómo se articularon esas piezas y qué dijeron los números una vez que estuvieron en su lugar.
Preprocesamiento del dataset
Antes de poder hacer cualquier pregunta interesante sobre estrategias de extracción, tiene que haber un set de datos. Un benchmark donde las entradas sean documentos reales, las etiquetas sean confiables, y todo pueda reconstruirse desde cero con un solo comando. Sin esa base, cualquier resultado posterior es no falsable.
Así que por aquí vamos a empezar: un paquete de Python pequeño y enfocado cuyo único trabajo es tomar la distribución original de Kleister NDA y devolver algo sobre lo que un pipeline moderno de extracción pueda realmente pararse—PDFs en disco, etiquetas estructuradas en Parquet, todo validado contra un esquema de Pydantic que los extractores van a compartir más adelante.
Reproducibilidad y contratos de datos compartidos
El preprocesamiento vive en su propio repositorio: kleister-nda-preparation. Expone un solo comando de CLI que lee las particiones TSV originales, parsea los strings crudos de las etiquetas, reubica los PDFs, y escribe archivos Parquet particionados.
Instalarlo como dependencia significa que los demás proyectos—la librería principal, el harness de evaluación, y, en la segunda parte, la infraestructura de despliegue—consumen todos la misma forma canónica de los datos.
Kleister NDA
Kleister NDA es un corpus de 540 documentos de acuerdos de confidencialidad (NDAs) recolectados de SEC Edgar, publicado por Applica AI como parte de un benchmark más amplio sobre Key Information Extraction en documentos largos y con estructuras visuales complejas.
Cada NDA está anotado con hasta cuatro campos:
- la
effective_dateen la que el contrato entra en vigor, - la
jurisdictionque lo rige, - la
partyo las partes que lo firman, y - el
termque especifica su duración.
Aquí va un ejemplo de cómo luce la estructura de los documentos en la práctica:

Un par de propiedades hacen de este un benchmark genuinamente útil:
- Primero, los documentos son reales: fueron enviados como anexos a presentaciones ante la SEC por empresas concretas, así que su estructura, el lenguaje legal, y los edge cases son todos auténticos.
- Segundo, son lo suficientemente largos como para importar realmente: la mayoría va entre una y veinte páginas, que es el punto a partir del cual las estrategias ingenuas de “poner todo en un solo prompt” comienzan a sentirse incómodas.
- Tercero, las reglas de normalización son estrictas: las fechas tienen que estar en ISO 8601, los términos deben reducirse a
{número}_{unidades}, y las jurisdicciones deben escribirse sin honoríficos. Ese último detalle es el que vuelve no trivial a la evaluación. Un modelo que devuelveState of New Yorkcuando el ground truth esNew_Yorkestá equivocado, aunque cualquiera podría llamarlo un empate.
Expectativas de referencia
El paper original (Stanisławek et al., 2021) define una base útil para calibrar nuestras expectativas. Su mejor baseline, un modelo layout-aware llamado LAMBERT construido sobre BERT, alcanzó un F1 global de 81.77% en el test set. Ese es el número a tener presente mientras se desarrolla el resto del artículo—es cómo se veía el estado del arte antes de los LLMs, y es lo que un extractor basado en un LLM bien configurado debería superar con comodidad.
Análisis exploratorio de datos
Antes de implementar una línea de código de extracción, hubo un notebook. La versión corta de lo que emergió del EDA es que la distribución de longitud de los documentos se encuentra sesgada hacia la derecha con una cola pesada—la mayoría de los NDAs tienen entre tres y siete páginas, pero algunos cuantos se estiran más allá de las veinte.
Distribuciones de longitud de los documentos
Cantidad de tokens, caracteres, y páginas
EDA para los NDAs
El notebook completo del análisis exploratorio, con cada gráfico y el código que lo produjo, vive en notebooks/initial-eda.ipynb. Vale la pena darle un vistazo si quieres ver cómo se ven los datos antes de que los componentes de extracción y la evaluación los toquen.
El EDA dejó al descubierto tres patrones, y cada uno de ellos empujó el diseño en una dirección específica.
- La distribución de longitud es asimétrica hacia la derecha. La mayoría de los NDAs se sientan cómodamente en el rango de 3,000 a 5,000 tokens repartidos en tres a siete páginas, pero las tres particiones exhiben el mismo comportamiento de cola larga, con outliers que se estiran hasta aproximadamente 14,000 tokens y 23 páginas.
- Las tasas de nulos varían drásticamente entre campos.
partynunca es nulo.jurisdictionrara vez es nulo.effective_dateestá ausente en aproximadamente el 25-30% de los documentos, ytermestá ausente en aproximadamente el 60-70%. Los campos con tasas de nulos altas son aquellos donde el riesgo de alucinación es más alto. - El texto OCR que viene con el dataset es más sucio de lo que debería. Sobre los mismos PDFs,
text_best(el texto derivado por OCR que forma parte del dataset original) y el texto extraído directamente vía PyMuPDF muestran una correlación casi perfecta de longitud pero una similitud de Jaccard que se concentra alrededor de 0.70-0.75—mismo tamaño, aunque ~25-30% de los tokens no coinciden. Esa es la huella característica del ruido del OCR sobre documentos nativos digitales: la distorsión a nivel de caracteres preserva la longitud de la cadena mientras corrompe tokens que el extractor obtendría gratis. Esto dio forma a una decisión a nivel de librería: extraer desde la capa de texto por defecto, y exponer un protocoloOCRProviderpara que los documentos escaneados sigan siendo un caso de primera clase. Para Kleister, PyMuPDF es la elección correcta.
El esquema como contrato y mecanismo de calibración
La decisión de diseño más importante de este proyecto es también la menos visible: el esquema de Pydantic no es solamente un tipo. Es el contrato, el validador, y el prompt—todo al mismo tiempo.
Aquí va una pieza pequeña de lo que eso significa en la práctica:
from pydantic import BaseModel, Field
class NDA(BaseModel):
"""
Extract key information from a Non-Disclosure Agreement (NDA).
General formatting rules:
* In attribute values, replace spaces ` ` and colons `:` with underscores `_`.
* If an attribute is not present or cannot be determined, return `null`.
"""
jurisdiction: str | None = Field(
None,
description=(
"The state or country under whose laws the contract is governed. "
"Return only the name (e.g., `New_York`, `Delaware`, `Florida`). "
"Do NOT include prefixes such as `State_of_` or `Commonwealth_of_`."
),
)El esquema como única fuente de verdad del comportamiento de extracción
El esquema completo, incluyendo los field validators, vive en src/nda/schema.py. Vale la pena leerlo para ver cómo el contrato, la validación, y la ingeniería de prompts se codifican todos en un mismo lugar.
Hay tres cosas pasando simultáneamente, así que vamos a separarlas una por una.
- La primera es el contrato. Cualquier código que consuma un resultado de extracción (el harness de evaluación, o una aplicación que integre estos resultados) puede confiar en que
jurisdictiones un string oNone, quepartyes siempre una lista, que las fechas son strings en formato ISO. Esto es absolutamente crucial para su uso en producción. - La segunda es la capa de validación. El esquema no solo describe la forma de las salidas; también la impone. Cuando un modelo devuelve una jurisdicción con un prefijo no deseado como
State_of_, un field validator lo remueve. Cuando el nombre de una parte vuelve envuelto en comillas tipográficas Unicode, esas se normalizan a ASCII. La validación corre simétricamente en tiempo de preprocesamiento (limpiando las etiquetas del ground truth) y en tiempo de inferencia (limpiando las predicciones), lo que significa que la evaluación está comparando peras con peras en vez de estar midiendo un mismatch de normalización disfrazado como un error del modelo. - La tercera es el mecanismo de steering. El método
with_structured_output(NDA)de LangChain serializa la clase de Pydantic al esquema de function calling que el modelo ve en tiempo de inferencia. Eso significa que el docstring de la clase, los tipos de los campos, y cada string dedescriptionen cadaField, pasan a ser parte del prompt. El modelo no ve una instrucción genérica de “extrae estos campos”; ve las reglas de formato exactas, los prefijos específicos que hay que evitar, y los ejemplos concretos de output válido.
Iteración dirigida por el esquema
Esto replantea cómo se itera sobre la calidad de la extracción. Cuando un LLM está sobre-especificando jurisdicciones sistemáticamente, no se va a un archivo de prompt separado a ajustar instrucciones del sistema, sino que se edita el description del campo jurisdiction y el cambio se propaga.
Queremos que el esquema sea la única superficie donde se calibra el comportamiento de extracción, lo que mantiene estable al prompt del sistema y vuelve auditables los cambios de comportamiento vía el historial de git.
Arquitectura del paquete
Con un benchmark confiable en su lugar, la siguiente pregunta es qué es exactamente lo que correrá contra este. La lógica de extracción podría haber vivido en el repo de evaluaciones como un puñado de scripts, pero eso colapsa la distinción entre lo que se está midiendo y aquello que lo mide.
Mantenerlos separados implica que la librería tiene que sostenerse por sí sola: una API limpia, una implementación tipada, y un conjunto de abstracciones que tengan sentido por fuera del contexto de Kleister.
El resultado es agentic-kie, un paquete de Python cuyo trabajo es tomar un PDF y un esquema de Pydantic y devolver una instancia validada de ese esquema. Todo lo demás (detección de capa de texto, ruteo a OCR, renderizado de imágenes, orquestación del LLM) es un detalle de implementación en el que la persona que llama la función no tiene que pensar.
La API pública
La forma de la API pública es la decisión de diseño más importante del paquete. Todo lo que viene aguas abajo se desprende de ella. Así se ve una llamada típica:
from pathlib import Path
from nda import NDA
from langchain_anthropic import ChatAnthropic
from agentic_kie import PDFLoader, AgenticExtractor
file_path = Path("nda.pdf")
document = PDFLoader().load(file_path)
model = ChatAnthropic(model="claude-haiku-4-5")
agent = AgenticExtractor(model=model, schema=NDA)
result = agent.extract(document)Cuatro líneas hacen el trabajo: cargar el PDF, instanciar un modelo, envolverlo en un extractor atado a un esquema, y extraer. El extractor no sabe qué modelo está usando. El modelo no sabe qué documento está leyendo. El esquema no sabe que ninguno de los dos existe. Esa separación es deliberada—cada pieza es intercambiable de forma independiente, que es lo que vuelve posible, en primer lugar, el benchmarking de la próxima sección.
Empaquetada y distribuida en PyPI
La librería está publicada como agentic-kie y se instala vía uv add agentic-kie, con extras opcionales para cada proveedor de modelos ([anthropic], [google], [openai], [bedrock], o [all]). Cualquier modelo de chat de LangChain serviría, los extras se proveen únicamente por conveniencia.
Las cuatro abstracciones centrales—PDFLoader, PDFDocument, OCRProvider, y el protocolo Extractor—están documentadas en detalle en el README, así que me ahorraré la recapitulación.
Lo que vale la pena decir aquí es que el paquete está organizado alrededor de un único eje de responsabilidad: la ingesta está separada de la representación, la representación está separada de la extracción, y las estrategias de extracción son intercambiables detrás de un protocolo compartido. Esa organización es de lo que realmente va esta sección.
Estrategias de extracción
Hay dos estrategias disponibles, y ambas satisfacen el mismo protocolo Extractor—un solo método extract(document) -> T que toma un PDFDocument y devuelve una instancia validada del esquema. El mismo input, el mismo output, aunque una maquinaria completamente distinta en el medio.
- Single-pass es el baseline obvio: una llamada estructurada al LLM sobre el documento completo, con el esquema vinculado vía function calling. La cadena se construye una sola vez al momento de instanciar y se reutiliza a lo largo de los documentos. Rápida, barata, stateless, y—como van a mostrar las evaluaciones de la próxima sección—sorpresivamente difícil de vencer.
- Agentic es la apuesta más interesante. Un ReAct agent equipado con herramientas de exploración de documentos (
get_page_count,read_text,load_images) limitadas al documento específico que se está extrayendo. El agente lee lo que necesita, en el orden en que lo necesita, y se detiene cuando tiene suficiente información para llenar el esquema. Más cara por llamada, más resiliente a la longitud del documento, y con más por demostrar.
Así se ve el grafo interno del extractor agéntico en LangGraph Studio:
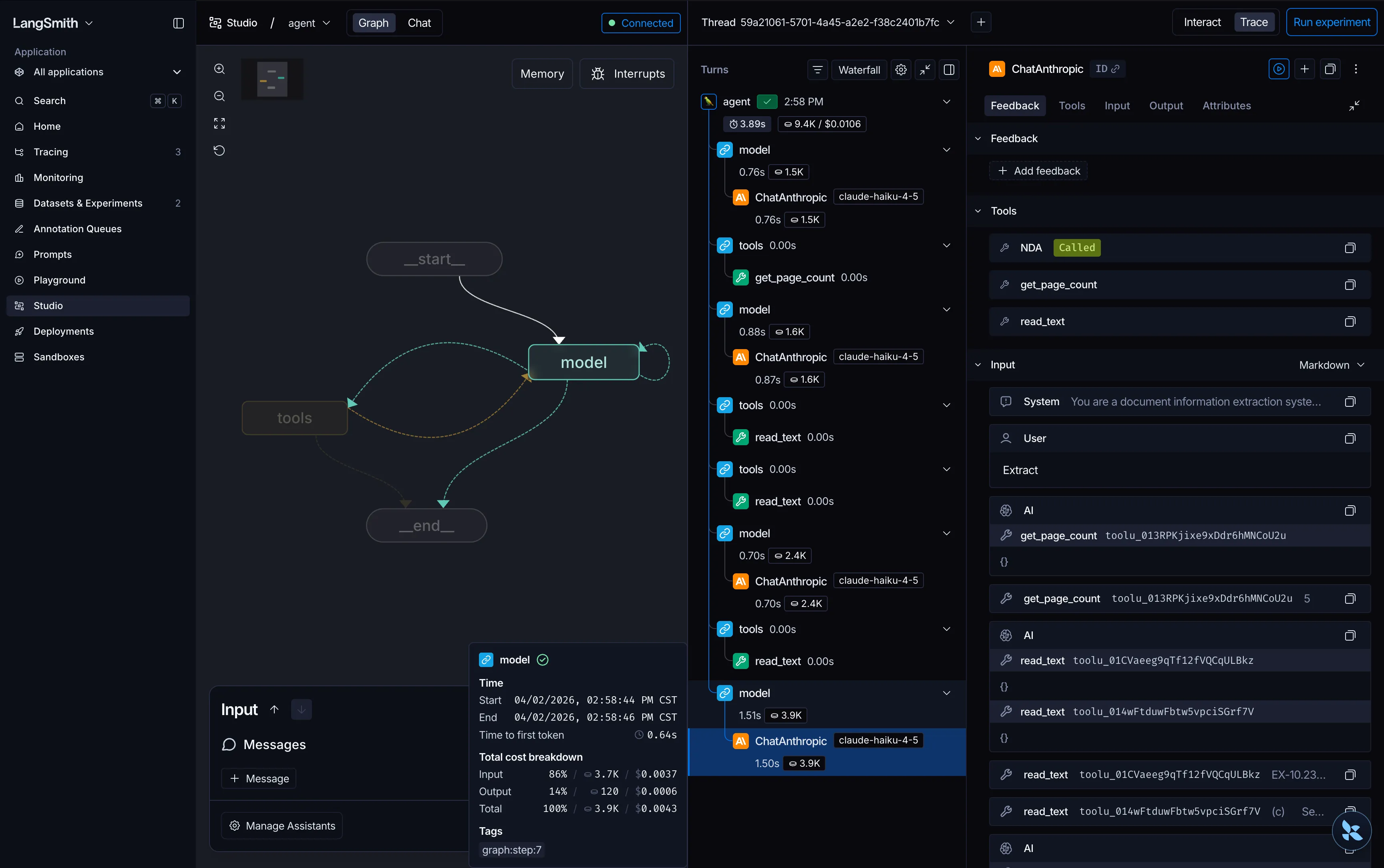
Un protocolo, dos estrategias
La implementación completa de ambos extractores, incluyendo el factory de herramientas de documento y el ReAct loop, viven en src/agentic_kie/. El directorio examples/ tiene scripts ejecutables que demuestran ambas estrategias a través de los proveedores usando el Kleister NDA dataset.
Argumentos de diseño
Dos decisiones de diseño moldearon al paquete de maneras que no son visibles desde la API pero que habrían sido problemáticas de no haber sido acertadas.
La primera fue desacoplar la carga de la representación. PDFLoader absorbe toda la complejidad del mundo real: detectar si existe una capa de texto, rutear a OCR cuando no existe, y validar el resultado. PDFDocument es inmutable, renderiza imágenes de forma lazy al primer acceso, y sirve tanto a estrategias de solo texto como multimodales sin saber cuál de las dos está a punto de consumirlo. El comportamiento agéntico existe en un espectro, y esta tarea de extracción tiene claramente un límite establecido, así que el agente no necesita de tanta libertad. Necesita una interfaz pequeña y curada sobre una representación confiable, no un entorno tipo REPL abierto.
La segunda fue elegir protocolo por sobre herencia para Extractor[T]. Single-pass y agentic satisfacen el mismo contrato extract(document) -> T sin estar forzadas a un árbol de herencia compartido. Las dos estrategias no tienen genuinamente nada en común internamente, y pretender lo contrario compartiendo una clase base abstracta habría sido una mentira disfrazada de reutilización de código. Un protocolo estructural da dispatch tipado en los límites donde importa (el harness de evaluación puede aceptar cualquier Extractor[NDA], por ejemplo) sin acoplar las implementaciones.
Evaluaciones
Con el conjunto de datos preparado y la librería en su lugar, la pregunta se desplaza de “¿podemos extraer?” a “¿qué tan bien, a qué costo, y bajo qué condiciones?”. El benchmark cubre tres proveedores de modelos (Anthropic, Google, y OpenAI) a través de dos tiers de capacidad cada uno (seleccionando la oferta actual de cada proveedor por tier a inicios de 2026) cruzados con ambas estrategias de extracción.
Doce configuraciones en total, puntuadas contra los mismos 83 documentos de la partición de desarrollo.
Tiers de modelo por proveedor
Modelos utilizados en los niveles de evaluación lite y estándar en los tres proveedores
| Proveedor | Lite | Estándar |
|---|---|---|
| Anthropic | Claude Haiku 4.5 | Claude Sonnet 4.6 |
| Gemini 3.1 Flash Lite (Preview) | Gemini 3 Flash (Preview) | |
| OpenAI | GPT 5.4 Mini | GPT 5.4 |
Alcance de este benchmark
Todos los resultados a continuación se calculan sobre la partición dev-0 de Kleister NDA (83 documentos). Es lo suficientemente grande como para rankear configuraciones e identificar patrones consistentes, aunque los hallazgos naturalmente se fortalecerían con una muestra más grande. La partición test-A queda disponible para quien quiera extender el análisis.
Ejecutando experimentos
Cada configuración es ejecutada como un experimento de LangSmith. El dataset NDA (los PDFs más labels_schema como salidas de referencia) se sube una sola vez como un dataset multimodal con los PDFs como adjuntos, y cada experimento evalúa contra los mismos ejemplos con los mismos evaluadores.
Este es un ejemplo de cómo luce la ejecución de un experimento en la UI de LangSmith:
Reproduciendo el benchmark
El harness completo de benchmarking (subida del dataset, ejecutor de experimentos, evaluadores, y scripts de agregación) vive en agentic-kie-evals. Los resultados crudos para cada configuración están publicados en data/results como CSVs por documento junto con resúmenes agregados, con el propósito de volver los resultados de esta entrada completamente auditables.
Resultados
Antes de interpretar los resultados, es importante considerar lo que el paper de Kleister reportaba sobre lo que era posible. El paper original de Kleister reporta un F1 de 81.77% para su mejor baseline layout-aware (LAMBERT) y un F1 de 97.86% para anotadores humanos sobre el conjunto de datos de prueba.
Estas son las cinco mejores configuraciones del benchmark, ordenadas por F1 global y anotadas con el costo y la latencia promedio por documento:
Las cinco mejores configuraciones de extracción
Configuraciones de mejor desempeño ordenadas por F1, con contexto de latencia y costo
| Proveedor | Nivel | Estrategia | Puntuación F1 | Latencia | Costo |
|---|---|---|---|---|---|
| Gemini | Estándar | Agente | 91.8% | 14.6s | $0.011 |
| Gemini | Estándar | Pasada única | 91.5% | 9.8s | $0.007 |
| GPT | Estándar | Pasada única | 89.9% | 2.1s | $0.011 |
| Gemini | Lite | Pasada única | 89.6% | 1.4s | $0.001 |
| GPT | Estándar | Agente | 89.5% | 8.5s | $0.024 |
El tope de la matriz es esencialmente un empate entre las configuraciones de la familia Gemini, con GPT pisándoles los talones. Gemini Standard Agentic se lleva el primer puesto con 91.8% de F1, pero Gemini Standard Single Pass alcanza 91.5% a aproximadamente el 70% del costo y el 65% de la latencia. Cada una de las cinco configuraciones del top supera al baseline (LAMBERT) por un margen cómodo, con los mejores resultados sentándose unos seis puntos por debajo del performance humano.
Mirando a lo largo de las doce configuraciones, emerge un patrón consistente. En cada proveedor y tier, la brecha de F1 entre agentic y single-pass se va cerrando a medida que aumenta la capacidad del modelo. En el lite tier, single-pass gana en los tres proveedores. En el standard tier, las estrategias convergen, con Claude y Gemini mostrando al enfoque agéntico un poco por delante.
Comparación de estrategias por proveedor y tier
Agentic vs. single pass para Claude, Gemini, y GPT
La latencia y el costo son donde la asimetría se vuelve drástica. Como era de esperar, la extracción agéntica es consistentemente más lenta y más cara que una única llamada, con Claude Standard Agentic llegando a ~65 segundos por documento a ~$0.038. Para una estrategia que, en el mejor de los casos, entrega una mejora modesta en F1 en el tope de la matriz, ese es un precio alto. Las ejecuciones agénticas en el lite tier son lo peor de ambos mundos: más lentas, más caras, y menos precisas que sus contrapartes en single-pass.
Análisis de fallas por campo
El F1 agregado esconde los modos de falla que realmente explican al benchmark. Desglosar los resultados por campo (effective_date, party, jurisdiction, y term) saca a la superficie un patrón que se sostiene en cada proveedor y tier.
Dónde falla la extracción
F1 exacto por campo a lo largo de todas las configuraciones
El paper marcaba a term como la entidad más difícil para los baselines pre-LLM (LAMBERT puntuó 55.03% de F1 en ese campo), y los resultados con LLMs confirman que sigue siendo el modo de falla más común. Las tres familias de modelos confunden consistentemente las duraciones de sub-cláusulas (períodos de supervivencia de la confidencialidad, períodos restringidos de no-competencia) con el término general del acuerdo. La descripción del campo en el esquema intenta guiar al modelo hacia la duración del acuerdo específicamente, pero cuando un documento contiene múltiples cláusulas de duración, los modelos en el lite tier se van hacia la que sea más prominente en el texto.
El ranking de los campos es estable a lo largo de las configuraciones, pero la profundidad de la falla varía dramáticamente bajo orquestación agéntica. Claude Lite Agentic y GPT Lite Agentic tocan fondo en los mismos dos campos: jurisdiction (63.9% y 51.8%) y term (66.3% y 56.6%). Los baselines del paper no hacen quedar bien a estos resultados: LAMBERT alcanzó 96.50% en jurisdiction y Flair encabezó el campo term con 60.33%. Un modelo de frontera corriendo un bucle agéntico puede retroceder por debajo de lo que lograban los baselines pre-LLM sobre los mismos campos. La tarea no cambia. La capacidad de ejecutarla bajo orquestación agéntica sí.
¿Cuándo vale la pena un agente?
Esta es la pregunta que motiva, de entrada, la arquitectura de dos estrategias. Los números agregados sugieren que utilizar un agente en esta tarea no es totalmente efectivo, pero los agregados pueden ocultar dinámicas a nivel de documento.
Graficar el delta de F1 por documento entre agentic y single-pass—segmentado por proveedor, tier, y longitud del documento—aumenta la claridad en los resultados.
El impacto de un agente a nivel de documento depende fuertemente del tier
Delta de F1 (agentic - single pass) por documento, por proveedor, tier, y longitud del documento
Delta F1 (agente - pasada única)
Los resultados en el lite tier cuentan una historia consistente en los tres proveedores: el enfoque agéntico hace retroceder a más documentos de los que mejora, y los clústeres rojos dominan en cada bucket de longitud. GPT Lite Agentic es el peor ofensor, retrocediendo 22 documentos cortos con un delta promedio de -0.44 F1 por documento. Incluso para Gemini 3.1 Flash Lite, el mejor de los modelos del tier lite, las mejoras son pequeñas y dispersas mientras que las regresiones son concentradas y severas.
El standard tier invierte la dinámica. Los resultados sin cambios dominan—los círculos grises crecen a 40+ observaciones por bucket—lo que significa que el agente y el extractor single-pass aterrizan en la misma respuesta la mayor parte del tiempo. Cuando divergen, las mejoras son más grandes y las regresiones son más raras. Claude Standard Agentic muestra una mejora impresionante de +0.60 en documentos cortos donde sí marca la diferencia, y GPT Standard Agentic muestra una mejora limpia de +0.83 en un documento muy largo que single-pass no pudo manejar.
Este patrón tiene dos mecanismos interactuando al mismo tiempo. La extracción single-pass es una sola decisión, mientras que la extracción agéntica son decenas de decisiones, y cada decisión requiere una capacidad de meta-razonamiento para la que los modelos más pequeños están menos equipados. La tarea de extracción en sí no es más difícil; la orquestación a su alrededor sí lo es. Y la orquestación tiene un segundo costo encima del primero: el agente tiene que acumular los hechos extraídos a lo largo de las tool calls y después sintetizarlos en el esquema final. Eso es un problema de working memory más difícil que producir un resultado estructurado desde una sola ventana de contexto, y los modelos más pequeños demuestran ser más propensos a olvidar o contradecir sus observaciones anteriores.
Un contraejemplo claro al reflejo de usar un agente para todo
El movimiento por defecto en LLM engineering ahora mismo es envolver una tarea en un loop agéntico y ver qué pasa. Este benchmark es un recordatorio de que el default no siempre es seguro: en la tarea equivocada, o con el modelo equivocado, es activamente peor que optar por la estrategia más simple.
Entonces, ¿cuándo vale la pena un agente? En este benchmark, no lo vale. El enfoque más simple domina la mayor parte de la matriz y degrada activamente el desempeño en los modelos del lite tier, mientras que las ganancias del standard tier son demasiado pequeñas como para justificar 2-4x de latencia y costo. Ese es un data point raro y útil contra el reflejo de envolver una tarea dentro de un agente, y el tipo de respuesta que solo se vuelve visible una vez que has construido ambas estrategias y ejecutado una comparación sistemática.
¿Ahora qué sigue?
Vale la pena señalar lo que es este benchmark y lo que no. La conclusión de que single-pass domina no es universal—es un hallazgo sobre Kleister NDA específicamente, con un esquema particular, una distribución de longitudes de documento, y una estructura de campos. Dominios distintos van a hacer emerger, naturalmente, dinámicas distintas.
La arquitectura de dos estrategias en agentic-kie existe porque la respuesta correcta a “¿acaso esto debería ser un agente o un workflow?” rara vez es obvia a priori; es algo que se aprende construyendo ambas estrategias y midiendo. Ese loop de aprendizaje—elegir una tarea, construir ambas estrategias detrás de un protocolo compartido, medir, tomar una decisión—es el entregable. El resultado negativo sobre el comportamiento agéntico es la prueba de que funciona.
Así que con la matriz medida y el ganador identificado, la pregunta de ingeniería se desplaza de “¿qué configuración?” hacia “¿cómo llevamos esto a producción?”. Gemini 3 Flash (el standard tier de Gemini) corriendo extracción single-pass es hacia lo que el benchmark apunta: 91.5% de F1 a ~$0.007 por documento y bajo los diez segundos de latencia, cómodamente por encima del baseline LAMBERT y bastante cerca del nivel humano.
La parte dos toma esa configuración y la conecta a un sistema productivo diseñado para escalar. Nos vemos ahí.